 В предыдущей статье шла речь об установки megacli для мониторинга дисков под LSI 2108 Megaraid контроллеров. Сейчас же я хочу немного описать мониторинг батареи (BBU) для RAID контроллеров в целом. Какие шаги нужно предпринимать и как не наделать лишних проблем для себя при возникновении ошибок или неполадок с BBU (Battery Backup Unit).
В предыдущей статье шла речь об установки megacli для мониторинга дисков под LSI 2108 Megaraid контроллеров. Сейчас же я хочу немного описать мониторинг батареи (BBU) для RAID контроллеров в целом. Какие шаги нужно предпринимать и как не наделать лишних проблем для себя при возникновении ошибок или неполадок с BBU (Battery Backup Unit).
Состояние батареи нужно периодически проверять. Для RAID контроллеров этот компонент вообще может отсутствовать, так как его основное предназначение – это держать в кэше данные, которые еще не записались на диск, т.е. сохранение целостности данных при сбое питания (внезапное отключения подачи электричества).
На данный момент, почти все рейд контроллеры поддерживают кэширование данных на уровне контроллера. Т.е. каждый физический диск имеет свой кэш плюс кэш контроллера. Такой подход повышает производительность системы при сохранение большого количества данных или же при очень высоком уровне отдачи контента конечным пользователям.
Если рейд контроллер умеет кэшировать данные, то на нем можно настроить политику считывания, записи и буферизации данных.
Read Policy: Политика считывания указывает каким образом контроллеру нужно считывать сектора логических устройств при поиске нужной информации.
- Read-Ahead. Когда используется политика упреждающего (на перед) чтение, контроллер включает режим последовательного считывания секторов с логических дисков при поиске данных. Производительность повышается, если данных записаны последовательно, сектор за сектором на логические диски.
- No-Read-Ahead. Режим отключения политика последовательного считывания данных на контроллере.
- Adaptive Read-Ahead. Когда включена адаптивная политика упреждающего чтение, контроллер инициализирует упреждающее чтение только если пришел запрос на очень часто считываемые данные, которые записаны последовательно на логический диск. Если же запрашиваются рендомные(записанные в случайной последовательности) данные – контроллер переходит в режим no-read-ahead.
Про политику записи и буферизации лучше читать в оригинале.
Write Policy: The write policies specify whether the controller sends a write-request completion signal as soon as the data is in the cache or after it has been written to disk.
- Write-Back. When using write-back caching, the controller sends a write-request completion signal as soon as the data is in the controller cache but has not yet been written to disk. Write-back caching may provide improved performance since subsequent read requests can more quickly retrieve data from the controller cache than they could from the disk. Write-back caching also entails a data security risk, however, since a system failure could prevent the data from being written to disk even though the controller has sent a write-request completion signal. In this case, data may be lost. Other applications may also experience problems when taking actions that assume the data is available on the disk.
В этом режиме как только данные попали в кэш – контроллер говорит, что данные уже сохранены. Это повышает производительность но ставит под угрозу целостность данных.
- Write-Through. When using write-through caching, the controller sends a write-request completion signal only after the data is written to the disk. Write-through caching provides better data security than write-back caching, since the system assumes the data is available only after it has been safely written to the disk.
В этом режиме данные попадать в кэш, записываются на дик и только тогда контроллер отвечает, что данные сохранены. Это повышает целостность данных, но уменьшает производительность.
Cache Policy: The Direct I/O and Cache I/O cache policies apply to reads on a specific virtual disk. These settings do not affect the read-ahead policy. The cache policies are as follows:
- Cache I/O. Specifies that all reads are buffered in cache memory.
Все считанные данные буферизируются в кэше.
- Direct I/O. Specifies that reads are not buffered in cache memory. When using direct I/O, data is transferred to the controller cache and the host system simultaneously during a read request. If a subsequent read request requires data from the same data block, it can be read directly from the controller cache. The direct I/O setting does not override the cache policy settings. Direct I/O is also the default setting.
Данные не буферизируются в кэше.
Теперь перейдем к практике на примере мегарейд контроллера.
Для начала нужно проверить логи:
root@il:~# megacli -fwtermlog -dsply -aall
Если вывелась куча строк типа:
02/13/14 6:30:57: EVT#715494-02/13/14 6:30:57: 150=Battery needs replacement - SOH Bad 02/13/14 6:32:02: Not enough charge capacity left in battery for expeded data retention duration 02/13/14 6:32:02: Battery needs replacement 02/13/14 6:32:02: EVT#715495-02/13/14 6:32:02: 150=Battery needs replacement - SOH Bad 02/13/14 6:33:07: Not enough charge capacity left in battery for expeded data retention duration 02/13/14 6:33:07: Battery needs replacement 02/13/14 6:33:07: EVT#715496-02/13/14 6:33:07: 150=Battery needs replacement - SOH Bad 02/13/14 6:34:12: Not enough charge capacity left in battery for expeded data retention duration 02/13/14 6:34:12: Battery needs replacement 02/13/14 6:34:12: EVT#715497-02/13/14 6:34:12: 150=Battery needs replacement - SOH Bad 02/13/14 6:35:17: Not enough charge capacity left in battery for expeded data retention duration 02/13/14 6:35:17: Battery needs replacement 02/13/14 6:35:17: EVT#715498-02/13/14 6:35:17: 150=Battery needs replacement - SOH Bad 02/13/14 6:36:22: Not enough charge capacity left in battery for expeded data retention duration 02/13/14 6:36:22: Battery needs replacement 02/13/14 6:36:22: EVT#715499-02/13/14 6:36:22: 150=Battery needs replacement - SOH Bad 02/13/14 6:37:27: Not enough charge capacity left in battery for expeded data retention duration 02/13/14 6:37:27: Battery needs replacement 02/13/14 6:37:27: EVT#715500-02/13/14 6:37:27: 150=Battery needs replacement - SOH Bad 02/13/14 6:38:32: Not enough charge capacity left in battery for expeded data retention duration 02/13/14 6:38:32: Battery needs replacement 02/13/14 6:38:32: EVT#715501-02/13/14 6:38:32: 150=Battery needs replacement - SOH Bad 02/13/14 6:39:37: Not enough charge capacity left in battery for expeded data retention duration
… первым делом проверяем статус BBU установленной тулзой:
root@il:~# megacli -adpbbucmd -aall BBU status for Adapter: 0 BatteryType: iBBU Voltage: 4008 mV Current: 0 mA Temperature: 26 C Battery State: Failed BBU Firmware Status: Charging Status : None Voltage : OK Temperature : OK Learn Cycle Requested : No Learn Cycle Active : No Learn Cycle Status : OK Learn Cycle Timeout : No I2c Errors Detected : No Battery Pack Missing : No Battery Replacement required : Yes Remaining Capacity Low : Yes Periodic Learn Required : No Transparent Learn : No No space to cache offload : No Pack is about to fail & should be replaced : No Cache Offload premium feature required : No Module microcode update required : No GasGuageStatus: Fully Discharged : No Fully Charged : Yes Discharging : Yes Initialized : Yes Remaining Time Alarm : No Discharge Terminated : No Over Temperature : No Charging Terminated : No Over Charged : No Relative State of Charge: 96 % Charger System State: 49168 Charger System Ctrl: 0 Charging current: 0 mA Absolute state of charge: 5161 % Max Error: 19 % Battery backup charge time : 0 hours BBU Capacity Info for Adapter: 0 Relative State of Charge: 96 % Absolute State of charge: 5161 % Remaining Capacity: 62706 mAh Full Charge Capacity: 65467 mAh Run time to empty: Battery is not being charged. Average time to empty: Battery is not being charged. Estimated Time to full recharge: Battery is not being charged. Cycle Count: 119 Max Error = 19 % Remaining Capacity Alarm = 120 mAh Remining Time Alarm = 10 Min BBU Design Info for Adapter: 0 Date of Manufacture: 12/01, 2010 Design Capacity: 1215 mAh Design Voltage: 3700 mV Specification Info: 33 Serial Number: 3241 Pack Stat Configuration: 0x64a0 Manufacture Name: LS1121001A Firmware Version : Device Name: 3150301 Device Chemistry: LION Battery FRU: N/A Transparent Learn = 0 App Data = 0 BBU Properties for Adapter: 0 Auto Learn Period: 30 Days Next Learn time: Thu Feb 20 06:33:27 2014 Learn Delay Interval:0 Hours Auto-Learn Mode: Enabled
Убеждаемся, что проблема есть по параметрам – Battery Replacement required : Yes и Battery State: Failed. Перед паникой и заменой, нужно дополнительно посмотреть параметр Run time to empty: Battery is not being charged. – Это означает, что нужно ее зарядить, так как она еще ни разу не заряжалась и состояние заряда :
Relative State of Charge: 96 %
Absolute State of charge: 5161 %
Значит первым делом нужно попробовать зарядить BBU и если не помогло – проверить все ли правильно подсоединено. Если проблема не решилась – нужно проводить замену.
Можно пользоваться этими шагами для определения и решения проблемы с BBU:
| Num | Type | Description | Indication | Actions |
| 2 | F | Unable to recover cache data from TBBU | A,B | 1 |
| 10 | F | Controller cache discarded due to memory/battery problems | A,B | 1 |
| 11 | F | Unable to recover cache data due to configuration mismatch | A,B,C | 1 |
| 146 | W | Battery voltage low | N/A | 1,2 |
| 162 | W | Current capacity of the battery is below threshold | B | 1,2 |
| 150 | F | Battery needs replacement – SOH Bad | D | 1,2 |
| 154 | W | Battery relearn timed out | D | 1,2 |
| 161 | W | Battery removed | D | 1,2 |
| 200 | C | Battery/charger problems detected: SOH Bad | D | 1,2 |
| 211 | C | BBU Retention test failed! | G | 1,2 |
| 142 | W | Battery Not Present | N/A | 1,2 |
| 253 | W | Battery requires reconditioning: please initiate a LEARN cycle | N/A | 3 |
| 307 | W | Periodic Battery Relearn is pending. Please initiate manual leam cycle as Automatic leam is not enabled | H | 3 |
| 195 | W | BBU disabled: changing WB to WT | E, F | 4,5 |
| 330 | W | Detected error with the remote battery connector cable | N/A | 6 |
Type:
F= Fatal. W=Warning. C=Critical.
Indication:
A) Sudden power loss or system hang, when BBU is not fully charged and Write Back mode is forcefully enabled
B) The extended power loss to the system has resulted in the BBU being thoroughly discharged before power recovery.
C) The specific virtual drive configuration may have changed, so that previous virtual drive information cannot be recovered from BBU data
D) BBU failure or it is installed or connected incorrectly.
E) BBU not connected or not fully charged.
F) If WB mode was enabled before BBU charge, then it will be automatically re-enabled after the charge
G) BBU not able to keep cache data long enough during system power off.
H) The battery requires a relearn cycle to re-calibrate itself.
Action
1) Check the BBU status to see if the BBU should be charged or replaced.
2) Check the cable, power connection, backplane, SATA/SAS port, and make sure the BBU is installed and connected correctly.
3) Use RAID Web Console 2 or RAID BIOS Console to initiate a battery re-learn cycle.
4) Wait until the BBU is fully charged before rebooting the system.
5) WB can still be used through Bad BBU mode under RAID Web Console 2 but unexpected
power failure may cause data loss.
6) Check if the remote battery connector cable is properly connected and functional.








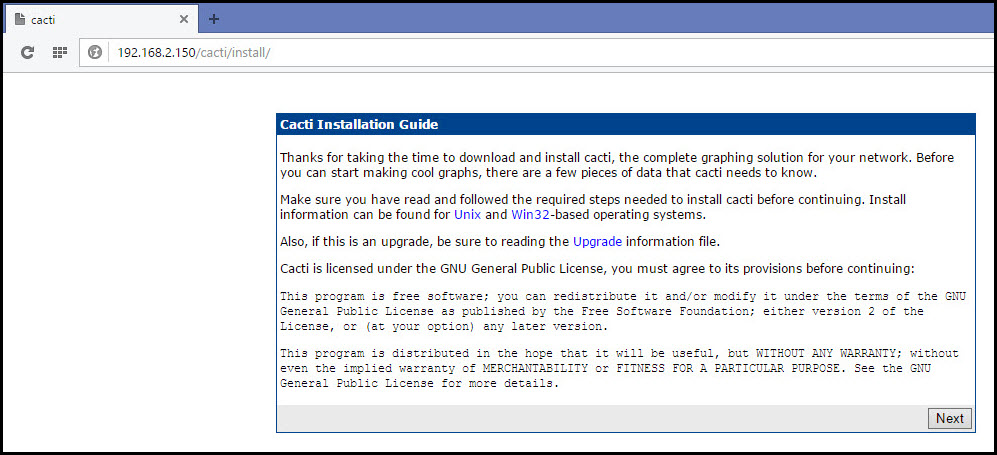
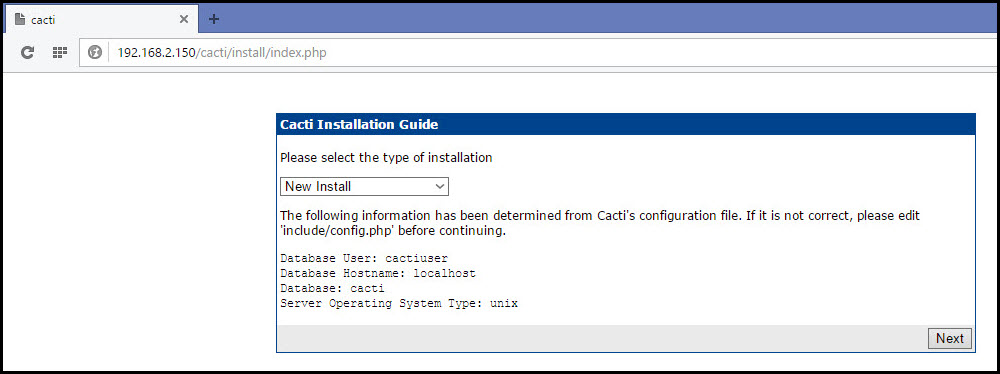
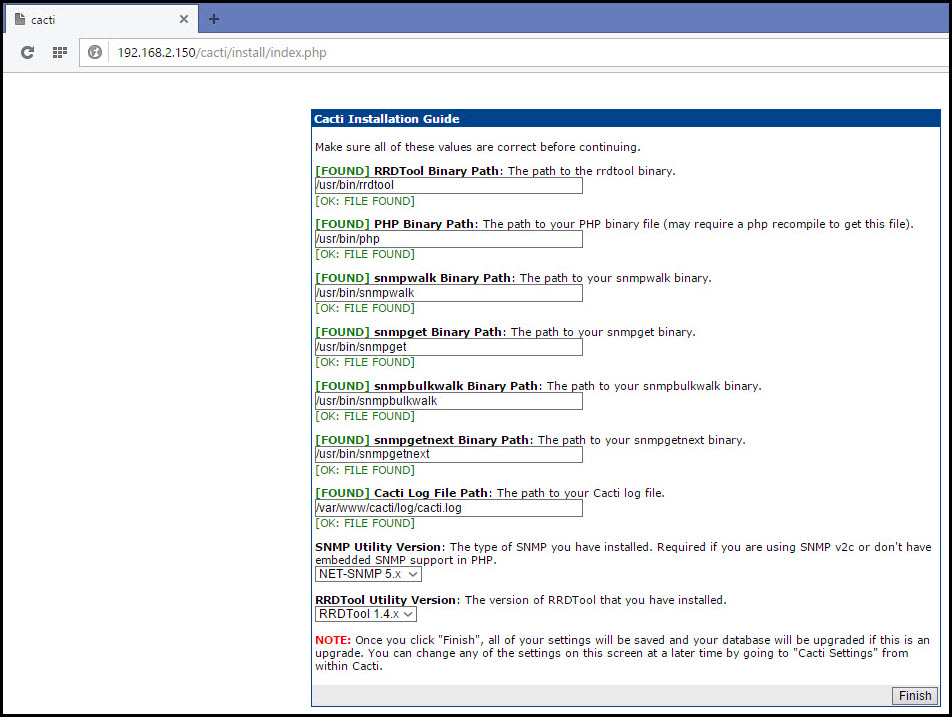



 После
После 

![Microsoft Windows 11 [10.0.28000.2113], Version 26H1 (Updated May 2026) -...](http://bitru.org/images/torrents/thumbs/220/1779556466_802_1.jpg)







